Multidimensional OLAP (MOLAP)
When the term "OLAP" was first coined it was used to refer to this type of OLAP. It was called "multidimensional" because the database on which it was based was "multidimensional," which is different from the relational, table-based databases we've discussed elsewhere on this blog (especially in the articles referring to the Process stage of the BI data life-cycle). There are a couple of ways you can think of this. If you're a math genius, imagine data stored in multidimensional arrays. If you're more business-oriented, imagine the data stored as if it were in a tabbed spreadsheet. A common application for such a sheet would be an income statement:

Obviously, we are interested in more than just this information. We can get this from our accounting department. We might also like to know about our profitability by product. We could think about our products like tabs with a sheet for every tab like this:

The beauty (and beast) of MOLAP is that in theory we can have as many nested tabs as we want. Suppose we added Countries to our list of dimensions. We could represent it like this:

In order to get at the information I want as quickly as possible, I want to try and load as much of the data as I can into memory on the file server that passes the numbers to me. Notice that I have a lot of flexibility in how I define the relationships between the items in my MOLAP database. The four quarters aggregate, or "roll up," to the total year, as would the products and countries to "All Products" or "All Countries." Yet I can also subtract cost from sales to compute margin. In aggregate such databases are called "hypercubes" (since they can go beyond three dimensions) or simply "cubes."
The downside to all this power and flexibility is that the more dimensions I add to my cube, the bigger (and more difficult to manage) the cube becomes. The tech gurus refer to this problem by the colorful term "database explosion." To get around this, developers have created other types of cubes that work differently, but are trickier to program, than the "traditional" MOLAP cube as described here.
Relational OLAP (ROLAP)
Another approach to getting around the database explosion problem of multidimensional OLAP is to do OLAP using table-based, relational databases of the kind described elsewhere on the blog. In one of those articles we showed a representation of a "star" schema database that looked like this:
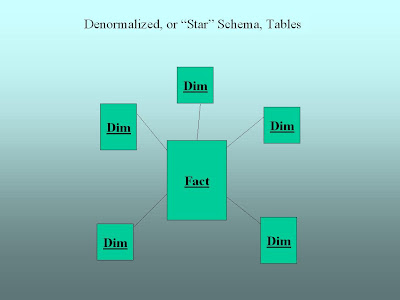
Relational OLAP (or ROLAP) is simply an attempt to make this table-based relational data behave like the cubes we talked about earlier. If you don't have a lot of data, this is slower than working with a cube. When you have the database explosion problem we talked about earlier, this approach can be a viable alternative to MOLAP.
Hybrid OLAP (HOLAP)
Hybrid OLAP is exactly what you might think from the name: an attempt to have the best of both multidimensional and relational OLAP by combining them. The way this works is that you keep the high-level data you want to get to quickly in a MOLAP cube and when you need detailed data the MOLAP cube passes a request for it to a relational database where the details are stored.
The Players
Most of the major BI vendors have an OLAP product. The best known are probably Oracle's Essbase, Microsoft's SQL Server Analysis Services (SSAS), and IBM Cognos' PowerPlay.
No comments:
Post a Comment