I don't normally devote a lot of space to a single company, but while researching to write about real-time business intelligence and analytics I ran across one I had never heard of before.
Vertica Systems specializes in databases that are built specifically for real-time and near real-time business intelligence and analytics. They claim database performance that is 50-1000 times faster than traditional data warehouses. How does Vertica accomplish this? In the most non-technical terms I can muster:
1. They organize the data differently than a traditional database, using a method called "columnar orientation." This makes it easier to get at just the data that are needed, faster than traditional queries.
2. They compress the data very aggressively. This allows them to, for example, store multiple copies of the same data sorted in different ways.
3. They store data for reading by queries differently than data to be written to the database, again to optimize the speed of data reads for queries.
4. They can take advantage of multiple processors on the database server.
5. Vertica wasn't designed to run on a specific kind of server hardware, but can run on anything that runs the Linux operating system. This should help hold down hardware costs.
Even though I hadn't heard of them, Vertica must be doing something right. They've quietly racked up an impressive client list that spans multiple industries. Clients include Twitter, Verizon, Bank of America, Comcast, Blue Cross Blue Shield, Sunoco, and most recently Groupon.
Thursday, January 27, 2011
Real-Time Business Intelligence: Technology and Strategy Implications
In an earlier article we discussed how increasing competition has led to the compression of the business intelligence life-cycle from a monthly to an almost continuous frequency in some cases. This challenges technology vendors and business strategists alike to respond to the new reality.
Technology Implications
When businesses updated their BI data monthly, processing of the data could be conveniently scheduled outside business hours. A processing window would be established (say, from 6 PM to 8 AM local time) for the data architects to extract, transform, and load (ETL) data from the transaction processing system such as sales orders or general ledger to the BI system. As demands for amounts and detail of BI data increased, it became more difficult to keep the processing within the allotted time window. But as long as this meant management occasionally had to wait until 10 AM or noon local time for monthly updates it wasn't a major problem. The flaw in this strategy was exposed by demands for more frequent updates.
Clearly what is needed from a technology standpoint is a more targeted and incremental approach to processing data. For example, a Microsoft SQL Server Analysis Services database (cube) can be programmed to monitor for changes in its source transaction system. After a change is detected, the cube can "listen" for a pre-determined amount of time to make sure there are no more changes to the source data, and then issue a request for only the new data. Since this represents a very small amount of data from the source system, and the portion of the cube that needs to be reprocessed is also quite small, the BI data update takes seconds instead of hours as in the old processing strategy. Other vendors are building similar capabilities. Another technique involves the use of database caching to constantly process changes to data in the background while continuing to present the latest available view of the data to the consumer.
Strategy Implications
Elsewhere on this site, I have advocated for a BI strategy that is in harmony with the way people interact with data. I introduced I concept I call the PRIME model, with five activities: Producing, Reviewing, Investigating, Monitoring, and Extrapolating. For more specifics, please feel free to click here. Based on the PRIME model, I can foresee three significant impacts on how businesses work with data as opposed to the current approach.
First, real-time BI and analytics will shift the focus of data consumption for knowledge workers, analysts and managers alike, from reviewing to monitoring. With a greatly reduced time window for the consumption of data before fresh data arrive, there simply won't be time to review and digest static reports. This will lead to a greater emphasis on business performance management. The traditional report will increasingly be boiled down to the presentation of a small number of key performance indicators (KPIs), along with strategic drivers of those KPIs.
Second, because data updates will occur too rapidly for a human analyst to investigate causes or extrapolate trends using traditional methods, there will be an increasing dependence on automated technologies for data mining and predictive analytics. The investigation and extrapolation performed through such automated technologies will feed into the monitoring I described in the last paragraph. These automated technologies will not supplant but will augment the knowledge worker, whose focus will shift toward longer-term strategic analyses.
Finally, the "24-hour BI cycle," as I described it in my previous article will drive an increasing reliance on mobile business intelligence, as managers and analysts require access to data wherever they are when business conditions change. IT will need the ability to push needed data to these knowledge workers, whether the client machine is a traditional PC, laptop, netbook, smartphone or tablet. It's not difficult to imagine that, over time the latter two devices will play a greater role as their capabilities and the wireless network infrastructure continue to improve.
Technology Implications
When businesses updated their BI data monthly, processing of the data could be conveniently scheduled outside business hours. A processing window would be established (say, from 6 PM to 8 AM local time) for the data architects to extract, transform, and load (ETL) data from the transaction processing system such as sales orders or general ledger to the BI system. As demands for amounts and detail of BI data increased, it became more difficult to keep the processing within the allotted time window. But as long as this meant management occasionally had to wait until 10 AM or noon local time for monthly updates it wasn't a major problem. The flaw in this strategy was exposed by demands for more frequent updates.
Clearly what is needed from a technology standpoint is a more targeted and incremental approach to processing data. For example, a Microsoft SQL Server Analysis Services database (cube) can be programmed to monitor for changes in its source transaction system. After a change is detected, the cube can "listen" for a pre-determined amount of time to make sure there are no more changes to the source data, and then issue a request for only the new data. Since this represents a very small amount of data from the source system, and the portion of the cube that needs to be reprocessed is also quite small, the BI data update takes seconds instead of hours as in the old processing strategy. Other vendors are building similar capabilities. Another technique involves the use of database caching to constantly process changes to data in the background while continuing to present the latest available view of the data to the consumer.
Strategy Implications
Elsewhere on this site, I have advocated for a BI strategy that is in harmony with the way people interact with data. I introduced I concept I call the PRIME model, with five activities: Producing, Reviewing, Investigating, Monitoring, and Extrapolating. For more specifics, please feel free to click here. Based on the PRIME model, I can foresee three significant impacts on how businesses work with data as opposed to the current approach.
First, real-time BI and analytics will shift the focus of data consumption for knowledge workers, analysts and managers alike, from reviewing to monitoring. With a greatly reduced time window for the consumption of data before fresh data arrive, there simply won't be time to review and digest static reports. This will lead to a greater emphasis on business performance management. The traditional report will increasingly be boiled down to the presentation of a small number of key performance indicators (KPIs), along with strategic drivers of those KPIs.
Second, because data updates will occur too rapidly for a human analyst to investigate causes or extrapolate trends using traditional methods, there will be an increasing dependence on automated technologies for data mining and predictive analytics. The investigation and extrapolation performed through such automated technologies will feed into the monitoring I described in the last paragraph. These automated technologies will not supplant but will augment the knowledge worker, whose focus will shift toward longer-term strategic analyses.
Finally, the "24-hour BI cycle," as I described it in my previous article will drive an increasing reliance on mobile business intelligence, as managers and analysts require access to data wherever they are when business conditions change. IT will need the ability to push needed data to these knowledge workers, whether the client machine is a traditional PC, laptop, netbook, smartphone or tablet. It's not difficult to imagine that, over time the latter two devices will play a greater role as their capabilities and the wireless network infrastructure continue to improve.
Tuesday, January 25, 2011
Real-Time Business Intelligence and Analytics: An Introduction
Previously we introduced the concept of a life-cycle for business intelligence data. Data are captured into transaction processing systems like the general ledger accounting system. At some interval these data are moved into a BI database and processed to make them suitable for consumption. At some point older data are archived or even removed when they are no longer useful.
At first the BI or decision support life-cycle was typically built around financial reporting, and thus depended on the quarterly or monthly accounting close. Once the books were closed for the accounting period, data were pulled from the accounting system, loaded into the BI or decision support database, reports were run, and data analyzed.
As BI moved beyond the financial realm, managers in business areas like Sales and Operations found that they could achieve competitive advantage by getting (and acting upon) more frequent updates of data as opposed to organizations that remained tied to the monthly accounting cycle. This spurred the increase in the frequency of data updates to weekly, daily, and so on. The result is an evolution toward a "24-hour BI cycle" that parallels the evolution toward a 24-hour news cycle in the news media. In some applications BI data are now updated almost continuously. Rather than being the exception, this high-frequency updating of data will increasingly become the rule.
The impetus toward real-time business intelligence and analytics has implications for both technology and business. Vendors are challenged to devise new solutions to the problems introduced by requirements for more frequent updates. With the increase in the amount and frequency of data updates, businesses need to rethink how they consume data. We'll address these issues in more detail in the next article.
At first the BI or decision support life-cycle was typically built around financial reporting, and thus depended on the quarterly or monthly accounting close. Once the books were closed for the accounting period, data were pulled from the accounting system, loaded into the BI or decision support database, reports were run, and data analyzed.
As BI moved beyond the financial realm, managers in business areas like Sales and Operations found that they could achieve competitive advantage by getting (and acting upon) more frequent updates of data as opposed to organizations that remained tied to the monthly accounting cycle. This spurred the increase in the frequency of data updates to weekly, daily, and so on. The result is an evolution toward a "24-hour BI cycle" that parallels the evolution toward a 24-hour news cycle in the news media. In some applications BI data are now updated almost continuously. Rather than being the exception, this high-frequency updating of data will increasingly become the rule.
The impetus toward real-time business intelligence and analytics has implications for both technology and business. Vendors are challenged to devise new solutions to the problems introduced by requirements for more frequent updates. With the increase in the amount and frequency of data updates, businesses need to rethink how they consume data. We'll address these issues in more detail in the next article.
Monday, January 24, 2011
Online Analytical Processing (OLAP), Continued
In the first of two articles discussing Online Analytical Processing (OLAP), we covered a bit of what OLAP is and how it was named. In this second introductory article, we'll discuss "flavors" of OLAP and try to cut through some of the "acronym fog" surrounding the concept.
Multidimensional OLAP (MOLAP)
When the term "OLAP" was first coined it was used to refer to this type of OLAP. It was called "multidimensional" because the database on which it was based was "multidimensional," which is different from the relational, table-based databases we've discussed elsewhere on this blog (especially in the articles referring to the Process stage of the BI data life-cycle). There are a couple of ways you can think of this. If you're a math genius, imagine data stored in multidimensional arrays. If you're more business-oriented, imagine the data stored as if it were in a tabbed spreadsheet. A common application for such a sheet would be an income statement:

Obviously, we are interested in more than just this information. We can get this from our accounting department. We might also like to know about our profitability by product. We could think about our products like tabs with a sheet for every tab like this:

The beauty (and beast) of MOLAP is that in theory we can have as many nested tabs as we want. Suppose we added Countries to our list of dimensions. We could represent it like this:

In order to get at the information I want as quickly as possible, I want to try and load as much of the data as I can into memory on the file server that passes the numbers to me. Notice that I have a lot of flexibility in how I define the relationships between the items in my MOLAP database. The four quarters aggregate, or "roll up," to the total year, as would the products and countries to "All Products" or "All Countries." Yet I can also subtract cost from sales to compute margin. In aggregate such databases are called "hypercubes" (since they can go beyond three dimensions) or simply "cubes."
The downside to all this power and flexibility is that the more dimensions I add to my cube, the bigger (and more difficult to manage) the cube becomes. The tech gurus refer to this problem by the colorful term "database explosion." To get around this, developers have created other types of cubes that work differently, but are trickier to program, than the "traditional" MOLAP cube as described here.
Relational OLAP (ROLAP)
Another approach to getting around the database explosion problem of multidimensional OLAP is to do OLAP using table-based, relational databases of the kind described elsewhere on the blog. In one of those articles we showed a representation of a "star" schema database that looked like this:
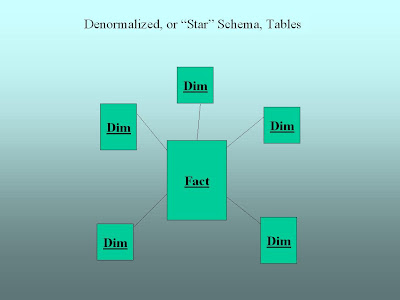
Relational OLAP (or ROLAP) is simply an attempt to make this table-based relational data behave like the cubes we talked about earlier. If you don't have a lot of data, this is slower than working with a cube. When you have the database explosion problem we talked about earlier, this approach can be a viable alternative to MOLAP.
Hybrid OLAP (HOLAP)
Hybrid OLAP is exactly what you might think from the name: an attempt to have the best of both multidimensional and relational OLAP by combining them. The way this works is that you keep the high-level data you want to get to quickly in a MOLAP cube and when you need detailed data the MOLAP cube passes a request for it to a relational database where the details are stored.
The Players
Most of the major BI vendors have an OLAP product. The best known are probably Oracle's Essbase, Microsoft's SQL Server Analysis Services (SSAS), and IBM Cognos' PowerPlay.
Multidimensional OLAP (MOLAP)
When the term "OLAP" was first coined it was used to refer to this type of OLAP. It was called "multidimensional" because the database on which it was based was "multidimensional," which is different from the relational, table-based databases we've discussed elsewhere on this blog (especially in the articles referring to the Process stage of the BI data life-cycle). There are a couple of ways you can think of this. If you're a math genius, imagine data stored in multidimensional arrays. If you're more business-oriented, imagine the data stored as if it were in a tabbed spreadsheet. A common application for such a sheet would be an income statement:

Obviously, we are interested in more than just this information. We can get this from our accounting department. We might also like to know about our profitability by product. We could think about our products like tabs with a sheet for every tab like this:

The beauty (and beast) of MOLAP is that in theory we can have as many nested tabs as we want. Suppose we added Countries to our list of dimensions. We could represent it like this:

In order to get at the information I want as quickly as possible, I want to try and load as much of the data as I can into memory on the file server that passes the numbers to me. Notice that I have a lot of flexibility in how I define the relationships between the items in my MOLAP database. The four quarters aggregate, or "roll up," to the total year, as would the products and countries to "All Products" or "All Countries." Yet I can also subtract cost from sales to compute margin. In aggregate such databases are called "hypercubes" (since they can go beyond three dimensions) or simply "cubes."
The downside to all this power and flexibility is that the more dimensions I add to my cube, the bigger (and more difficult to manage) the cube becomes. The tech gurus refer to this problem by the colorful term "database explosion." To get around this, developers have created other types of cubes that work differently, but are trickier to program, than the "traditional" MOLAP cube as described here.
Relational OLAP (ROLAP)
Another approach to getting around the database explosion problem of multidimensional OLAP is to do OLAP using table-based, relational databases of the kind described elsewhere on the blog. In one of those articles we showed a representation of a "star" schema database that looked like this:
Relational OLAP (or ROLAP) is simply an attempt to make this table-based relational data behave like the cubes we talked about earlier. If you don't have a lot of data, this is slower than working with a cube. When you have the database explosion problem we talked about earlier, this approach can be a viable alternative to MOLAP.
Hybrid OLAP (HOLAP)
Hybrid OLAP is exactly what you might think from the name: an attempt to have the best of both multidimensional and relational OLAP by combining them. The way this works is that you keep the high-level data you want to get to quickly in a MOLAP cube and when you need detailed data the MOLAP cube passes a request for it to a relational database where the details are stored.
The Players
Most of the major BI vendors have an OLAP product. The best known are probably Oracle's Essbase, Microsoft's SQL Server Analysis Services (SSAS), and IBM Cognos' PowerPlay.
Thursday, January 20, 2011
BI Concept: Online Analytical Processing (OLAP)
As we've discussed elsewhere on this site, business intelligence data have a life-cycle like other parts of the business, beginning with capturing, then processing, consuming, and finally archiving the data. The computer systems associated with the first, or Capture phase of the life-cycle, are typically referred to as Online Transaction Processing (OLTP) systems. These systems are usually designed, as we've noted, for getting data in rather than out.
OLTP systems were around for some time before anyone got the idea to dump data out of them and into a separate system for analysis purposes. Based on the notion of an OLTP system being one in which business data are captured as transactions, one would think that any system designed for data analysis should be designated as an Online Analytical Processing (OLAP) system. Not so.
The OLAP acronym was, in fact, born in controversy. It was coined in the early 1990's by relational database pioneer Dr. E. F. Codd. Dr. Codd had been consulting for Arbor Software, who had just introduced a new multidimensional database engine called "Essbase." He published a paper outlining what an OLAP database should do, and lo! it said that an OLAP database should do what Essbase does! When it was later revealed that Dr. Codd had been a paid consultant for Arbor, he lost credibility in the IT industry. But the definition of OLAP had been established to mean a very specific type of database. Over the course of time, this definition has evolved somewhat.
OLTP systems were around for some time before anyone got the idea to dump data out of them and into a separate system for analysis purposes. Based on the notion of an OLTP system being one in which business data are captured as transactions, one would think that any system designed for data analysis should be designated as an Online Analytical Processing (OLAP) system. Not so.
The OLAP acronym was, in fact, born in controversy. It was coined in the early 1990's by relational database pioneer Dr. E. F. Codd. Dr. Codd had been consulting for Arbor Software, who had just introduced a new multidimensional database engine called "Essbase." He published a paper outlining what an OLAP database should do, and lo! it said that an OLAP database should do what Essbase does! When it was later revealed that Dr. Codd had been a paid consultant for Arbor, he lost credibility in the IT industry. But the definition of OLAP had been established to mean a very specific type of database. Over the course of time, this definition has evolved somewhat.
Wednesday, January 19, 2011
Are You In The Market For An Appliance?
There's a lot of buzz in the business intelligence world these days about appliances. At first blush the term sounds confusing. It evokes images of something you would find in your kitchen rather than in the IT server room. In fact, appliances for business intelligence applications have been around in some form for decades.
So what's an appliance?
In the 1980's, the advent of personal computers and networking made it possible for small businesses to enter the computer age in great numbers for the first time. Unfortunately, most small business owners lacked either the time or skill to put together an integrated business solution. And if the business owners could find people with the time and necessary skill, they couldn't afford them. This created opportunities for systems integrators who stepped in with bundled hardware and software solutions, tailored for specific business applications. Such solutions were called "turnkey systems," because it was already installed and configured and all you needed to do was "turn the key" and drive the system.
Fast forward a few years and vendors responding to the need for "turnkey" solutions for data warehousing began building and configuring "data warehouse appliances" along very similar principles. The appliance is a bundle of hardware and software that has been pre-configured and optimized for a specific application, such as data warehousing. (Need background on data warehousing, schemas, etc.? Review Parts One and Two on processing data in the BI data life-cycle and the Data Warehouse Imperative.)
Why would I want an appliance?
You can make a very strong business case for buying an appliance rather than trying to build your business intelligence or data warehouse solution from scratch. Some of the key advantages are listed below:
The hardware and software are pre-selected and installed for you.
The system is configured and sold based on the amount of data you're pulling out of your source system, removing much of the guesswork involved in tweaking the system for performance.
Many appliances come with extras like administration consoles, to make system management easier. This can be a major consideration for small or medium sized businesses.
The appliance vendor becomes the single point of contact for all support. This can be huge. Just ask your IT person how many times he or she has stressed over troubleshooting system issues when the hardware vendor is blaming the software vendor and vice versa. And how much money has that, in turn, cost you?
So what's the catch?
You would think that for providing all this wonderful service, the integrator who puts this all together would charge a stiff premium over the cost of the hardware and software components bought separately. Actually, Gartner Research has found that this is not the case. But all is not paradise. You still have to design and maintain the database side of the data warehouse, or schema. Many vendors have pre-built schemas available, but these are only starting points for you to customize for your business.
Before I bought a data warehouse appliance (or similar - Microsoft has, for example, just released a "decision support" appliance bundle) I would ask some pointed questions of my prospective vendor partner:
Can I talk to other customers that you've worked with before to gain the benefit of their experience with you?
If I'm a growing business, how much flexibility do I have to expand as my needs change? How much is that going to cost me?
Are you (vendor) willing to commit to a long-term business relationship? And how will that work from your end?
And, of course, many others that are typical for any vendor/customer relationship, like service levels, do we get any cool logo schwag, etc.
Who are the major players?
Beside the aforementioned Microsoft, most of the big BI vendors participate in this market, either directly (Teradata) or through proxies (for example Netezza, a former independent now part of IBM).
So what's an appliance?
In the 1980's, the advent of personal computers and networking made it possible for small businesses to enter the computer age in great numbers for the first time. Unfortunately, most small business owners lacked either the time or skill to put together an integrated business solution. And if the business owners could find people with the time and necessary skill, they couldn't afford them. This created opportunities for systems integrators who stepped in with bundled hardware and software solutions, tailored for specific business applications. Such solutions were called "turnkey systems," because it was already installed and configured and all you needed to do was "turn the key" and drive the system.
Fast forward a few years and vendors responding to the need for "turnkey" solutions for data warehousing began building and configuring "data warehouse appliances" along very similar principles. The appliance is a bundle of hardware and software that has been pre-configured and optimized for a specific application, such as data warehousing. (Need background on data warehousing, schemas, etc.? Review Parts One and Two on processing data in the BI data life-cycle and the Data Warehouse Imperative.)
Why would I want an appliance?
You can make a very strong business case for buying an appliance rather than trying to build your business intelligence or data warehouse solution from scratch. Some of the key advantages are listed below:
The hardware and software are pre-selected and installed for you.
The system is configured and sold based on the amount of data you're pulling out of your source system, removing much of the guesswork involved in tweaking the system for performance.
Many appliances come with extras like administration consoles, to make system management easier. This can be a major consideration for small or medium sized businesses.
The appliance vendor becomes the single point of contact for all support. This can be huge. Just ask your IT person how many times he or she has stressed over troubleshooting system issues when the hardware vendor is blaming the software vendor and vice versa. And how much money has that, in turn, cost you?
So what's the catch?
You would think that for providing all this wonderful service, the integrator who puts this all together would charge a stiff premium over the cost of the hardware and software components bought separately. Actually, Gartner Research has found that this is not the case. But all is not paradise. You still have to design and maintain the database side of the data warehouse, or schema. Many vendors have pre-built schemas available, but these are only starting points for you to customize for your business.
Before I bought a data warehouse appliance (or similar - Microsoft has, for example, just released a "decision support" appliance bundle) I would ask some pointed questions of my prospective vendor partner:
Can I talk to other customers that you've worked with before to gain the benefit of their experience with you?
If I'm a growing business, how much flexibility do I have to expand as my needs change? How much is that going to cost me?
Are you (vendor) willing to commit to a long-term business relationship? And how will that work from your end?
And, of course, many others that are typical for any vendor/customer relationship, like service levels, do we get any cool logo schwag, etc.
Who are the major players?
Beside the aforementioned Microsoft, most of the big BI vendors participate in this market, either directly (Teradata) or through proxies (for example Netezza, a former independent now part of IBM).
Tuesday, January 18, 2011
Taking a Breather
Thanks for stopping by. I'm taking a break from writing this evening (US Central Time) but have several BI-related topics I want to research and write with a business focus. Here are a few:
- Online Analytical Processing (OLAP)
- Data Warehouse Appliances
- Performance Management (including the Balanced Scorecard)
- News and trends in BI and their potential business impact
Feel free to suggest other topics you would like to see in the blog by leaving a comment. I promise a quick response. Take care.
- Online Analytical Processing (OLAP)
- Data Warehouse Appliances
- Performance Management (including the Balanced Scorecard)
- News and trends in BI and their potential business impact
Feel free to suggest other topics you would like to see in the blog by leaving a comment. I promise a quick response. Take care.
Monday, January 17, 2011
Small Business Intelligence: Think BI(g)
Over the past few months we've talked about many facets of BI, from the data life-cycle to how people consume data. We've discussed BI concepts and will continue to do so. But what if you're an entrepreneur just starting out? If you read this blog you must be thinking, "this is all well and good for someone who's got money to spend on software and hardware, but I'm bootstrapping here! Come on!" OK, so maybe you can't start at the top. But you can start thinking in strategic business intelligence terms from Day One. How? The key is your business plan.
A well-crafted business plan answers critical questions about how you believe your business will be successful, including (not necessarily in this order):
What does the market need?
Who in the market needs it?
What makes me uniquely suited to meet the need?
How am I going to meet the need?
How am I going to find all those needy people? (or, how are they going to find me?)
and, of course...
How am I going to make this pay?
Just from that list you have the beginnings of your business intelligence strategy. What does the market need? A product or service. Who needs it? Customers. How will I find the customers and meet their needs? Through advertising and distribution channels. And how will I know if it's paying off? By measuring key metrics like revenue, operating profit, and cash flow against the financial plan spreadsheets I used to secure funding from the bank (or from Uncle Anton).
So, are you ready to begin?
In looking at accounting packages, find out if the one you're interested in has an export capability. That way, if your package doesn't have the reporting and analysis capabilities you want you can export to Excel and set up your own analysis. If you're using an e-commerce shopping cart, find out if it can export data. Between these options you should be able to get Customer and Product information, as well as key financial data. Especially starting out, those are the two key dimensions. (Don't know what a dimension is? Forget? For a quick review check out the articles on processing data, Parts One and Two.) If you're working with an accountant or bookkeeper, he or she may be able to help you get set up.
Even if you don't have a lot of money to spend it's never too early to start thinking BI(g).
A well-crafted business plan answers critical questions about how you believe your business will be successful, including (not necessarily in this order):
What does the market need?
Who in the market needs it?
What makes me uniquely suited to meet the need?
How am I going to meet the need?
How am I going to find all those needy people? (or, how are they going to find me?)
and, of course...
How am I going to make this pay?
Just from that list you have the beginnings of your business intelligence strategy. What does the market need? A product or service. Who needs it? Customers. How will I find the customers and meet their needs? Through advertising and distribution channels. And how will I know if it's paying off? By measuring key metrics like revenue, operating profit, and cash flow against the financial plan spreadsheets I used to secure funding from the bank (or from Uncle Anton).
So, are you ready to begin?
In looking at accounting packages, find out if the one you're interested in has an export capability. That way, if your package doesn't have the reporting and analysis capabilities you want you can export to Excel and set up your own analysis. If you're using an e-commerce shopping cart, find out if it can export data. Between these options you should be able to get Customer and Product information, as well as key financial data. Especially starting out, those are the two key dimensions. (Don't know what a dimension is? Forget? For a quick review check out the articles on processing data, Parts One and Two.) If you're working with an accountant or bookkeeper, he or she may be able to help you get set up.
Even if you don't have a lot of money to spend it's never too early to start thinking BI(g).
Sunday, January 16, 2011
BI Concept: Master Data Management (MDM)
When I first introduced readers of this blog to business intelligence I claimed that, by definition, BI had to be "integrated and coordinated" in order to be successful. I gave the example of the boss who, confronted with two or more sets of sales data, wondered in frustration which was correct. I could just as easily have made the example about the boss wondering which of several customer or product lists was correct. I made further allusions to this concept in discussing capture of data as the first step in the BI data life-cycle. And this is a major consideration in using extraction, transformation, and loading (ETL) tools to clean up such problems.
Unfortunately, this cleanup is not always fed back to the front-line systems where the data are initially captured. And there may be many such systems: lead generation systems, sales order systems, accounts receivable, and so on. And in most cases front-line workers are looking at the transaction systems they use daily, not the data warehouse.
This problem is the impetus for master data management (MDM). Simply put, the goal of MDM is to ensure that the view of company data is uniform across all business units and systems. There are two pieces to this. The first piece is to create a master data set for each of the critical dimensions (such as Customer or Product) of interest. The idea is that by referring to the master data set all parts of the business have a unified view of business data. This is depicted in the slide below.

This sounds like a terrific idea, but it leaves your front-line people looking in two different places, their data entry system, and the master data, for information they need. So the second, and much more difficult, piece is to integrate the master data back into the source systems, for example as in the next slide.

There are several approaches to doing this: by programming the source system to always look at the master data, or by actually re-writing source system data with master data, or any number of other strategies.
Sounds like a lot of work!
The notion of trying to tie every major element of interest together across all business units and systems can sound daunting. Many businesses choose to focus on specific areas of the business that they feel are most critical to their success. Thus you'll hear about Customer Data Integration (CDI), or Product Data Integration (PDI), or variations of such acronyms. Think of these as subsets of MDM that are focused on those specific subject areas.
Who are the players?
As you might imagine, many of the major vendors in BI in general are well represented in the MDM field. These include IBM, Oracle, Informatica, and SAP. But there are some lesser known companies in Gartner's "Magic Quadrant," among them Tibco, DataFlux, and VisionWare.
Unfortunately, this cleanup is not always fed back to the front-line systems where the data are initially captured. And there may be many such systems: lead generation systems, sales order systems, accounts receivable, and so on. And in most cases front-line workers are looking at the transaction systems they use daily, not the data warehouse.
This problem is the impetus for master data management (MDM). Simply put, the goal of MDM is to ensure that the view of company data is uniform across all business units and systems. There are two pieces to this. The first piece is to create a master data set for each of the critical dimensions (such as Customer or Product) of interest. The idea is that by referring to the master data set all parts of the business have a unified view of business data. This is depicted in the slide below.

This sounds like a terrific idea, but it leaves your front-line people looking in two different places, their data entry system, and the master data, for information they need. So the second, and much more difficult, piece is to integrate the master data back into the source systems, for example as in the next slide.

There are several approaches to doing this: by programming the source system to always look at the master data, or by actually re-writing source system data with master data, or any number of other strategies.
Sounds like a lot of work!
The notion of trying to tie every major element of interest together across all business units and systems can sound daunting. Many businesses choose to focus on specific areas of the business that they feel are most critical to their success. Thus you'll hear about Customer Data Integration (CDI), or Product Data Integration (PDI), or variations of such acronyms. Think of these as subsets of MDM that are focused on those specific subject areas.
Who are the players?
As you might imagine, many of the major vendors in BI in general are well represented in the MDM field. These include IBM, Oracle, Informatica, and SAP. But there are some lesser known companies in Gartner's "Magic Quadrant," among them Tibco, DataFlux, and VisionWare.
Thursday, January 13, 2011
Mobile Business Intelligence: Some Strategic Considerations
In my last post I presented my assessment that 2011 will prove to be a watershed year for mobile BI. I noted that wireless infrastructure, devices, and software applications are maturing to the point where mobile BI deployments will expand rapidly, in this and the coming years. Now I want to look at strategic considerations for business in deploying mobile business intelligence.
To begin I want to examine mobile BI in the context of the PRIME model I have presented elsewhere on this blog. From a device standpoint, I think it's very clear that tablet devices such as the Apple iPad or Samsung Galaxy Tab are best suited to most of the functions (Produce, Review, Investigate, Extrapolate) of data interaction I describe in the model. I say this due to the limited amount of screen area available on most smartphones.
The exception for me is the Monitor function, where a smartphone app could be a very useful client for performance management alerts. Such an app could present the mobile decision maker with up to the minute information, say, a change in a key performance indicator. The decision maker could then delegate investigation to an appropriate knowledge worker -- either through the app itself or with a good old-fashioned phone call. A smartphone with a larger screen and/or higher resolution might work for basic queries or reports.
As to mobile BI deployment, I would not be surprised to see small- and medium-sized businesses out in front of their larger counterparts. The reason I say this is that small and medium businesses are most likely to have immediate need of the flexibility that mobile BI provides. After all, in a larger business with a more mature BI implementation knowledge workers are likely to be equipped with laptops and working either at the office or at home. More time and improvements in device performance may be needed before these companies see tablet devices as ready for "industrial-strength" deployment to their back-office workers. I could more easily see initial deployment to front-line workers that the company wants to empower, for example, with customer intelligence in real- or near-real time.
In a smaller company by contrast, managers and even executives may already be on the front line and/or need to double as analysts. The ability to perform mobile analysis would be most welcome for them. (Those who have seen the iPad commercials currently running in the US are probably salivating already.) And if the business were using a software as a service (SaaS) model any performance disadvantage should be minimized since the heavy lifting is being done in the cloud. If you missed my post on SaaS check it out here. Oh, and don't skimp on the bandwidth.
To begin I want to examine mobile BI in the context of the PRIME model I have presented elsewhere on this blog. From a device standpoint, I think it's very clear that tablet devices such as the Apple iPad or Samsung Galaxy Tab are best suited to most of the functions (Produce, Review, Investigate, Extrapolate) of data interaction I describe in the model. I say this due to the limited amount of screen area available on most smartphones.
The exception for me is the Monitor function, where a smartphone app could be a very useful client for performance management alerts. Such an app could present the mobile decision maker with up to the minute information, say, a change in a key performance indicator. The decision maker could then delegate investigation to an appropriate knowledge worker -- either through the app itself or with a good old-fashioned phone call. A smartphone with a larger screen and/or higher resolution might work for basic queries or reports.
As to mobile BI deployment, I would not be surprised to see small- and medium-sized businesses out in front of their larger counterparts. The reason I say this is that small and medium businesses are most likely to have immediate need of the flexibility that mobile BI provides. After all, in a larger business with a more mature BI implementation knowledge workers are likely to be equipped with laptops and working either at the office or at home. More time and improvements in device performance may be needed before these companies see tablet devices as ready for "industrial-strength" deployment to their back-office workers. I could more easily see initial deployment to front-line workers that the company wants to empower, for example, with customer intelligence in real- or near-real time.
In a smaller company by contrast, managers and even executives may already be on the front line and/or need to double as analysts. The ability to perform mobile analysis would be most welcome for them. (Those who have seen the iPad commercials currently running in the US are probably salivating already.) And if the business were using a software as a service (SaaS) model any performance disadvantage should be minimized since the heavy lifting is being done in the cloud. If you missed my post on SaaS check it out here. Oh, and don't skimp on the bandwidth.
Wednesday, January 12, 2011
Mobile Business Intelligence On The Way
There are definite signs that 2011 will be a watershed year for mobile business intelligence. Among their predictions for 2011, Gartner Research projects that fully one-third of all BI will be consumed by handheld devices within two years. Vendor Microstrategy includes three mobile BI items in their top ten highlights for 2010. On January 12 Forbes reported that 90% of IT managers surveyed plan to deploy mobile apps this year. SAP BusinessObjects, which tweeted the link to the Forbes article, is obviously interested in some of that mobile app business. And so it goes.
What's driving the move to mobile BI now? Improvements in hardware and infrastructure. Smartphones have become smart indeed, and tablet devices such as the Apple iPad and Samsumg Galaxy Tab have already rendered netbooks all but obsolete. Meanwhile, the advent of 4G broadband in the US means that wireless mobile devices have access to data speeds comparable to those available on the fastest wired networks.
To be sure, not everyone is yet sold on the new tablets. IBM reported from this week's National Retail Federation show (as tweeted by Cognos) that tablets drove the highest positive and negative sentiment over the holidays. But development is progressing rapidly: Motorola, Dell, and RIM (Blackberry) are just three companies working on bringing dual-core processing capabilities to tablets in the very near future.
Next time we'll ponder how (not to mention if) you should approach mobile BI for your business.
What's driving the move to mobile BI now? Improvements in hardware and infrastructure. Smartphones have become smart indeed, and tablet devices such as the Apple iPad and Samsumg Galaxy Tab have already rendered netbooks all but obsolete. Meanwhile, the advent of 4G broadband in the US means that wireless mobile devices have access to data speeds comparable to those available on the fastest wired networks.
To be sure, not everyone is yet sold on the new tablets. IBM reported from this week's National Retail Federation show (as tweeted by Cognos) that tablets drove the highest positive and negative sentiment over the holidays. But development is progressing rapidly: Motorola, Dell, and RIM (Blackberry) are just three companies working on bringing dual-core processing capabilities to tablets in the very near future.
Next time we'll ponder how (not to mention if) you should approach mobile BI for your business.
BI Strategy: Summary
The previous material has introduced some basic BI concepts. The following list briefly summarizes what we’ve discussed over the past month or so.
1. BI data have a distinct lifecycle that consists of Capture, Processing, Consumption, and Archival.
2. The more accurately and precisely data are captured at the beginning of the lifecycle, the less work will need to be done in processing later.
3. BI data should be maintained separately from daily transaction data if at all possible.
4. Data integration and governance processes are critical to getting the most out of your firm’s business intelligence. These processes may be formal or informal, but ignore them at your peril.
5. The key to ensuring that steps 3 and 4 are executed properly is extraction, transformation, and loading of data (ETL) from the transaction system where the data are captured to the data warehouse or other data store where they will be consumed.
6. Your choices for consuming data are conditioned on the kinds of questions you want to ask and how you want to interact with the data.
7. Humans interact with data in one or more of five ways: producing, reviewing, investigating, monitoring, and extrapolating (PRIME).
8. Archival policy for BI data may be driven mainly by legal or tax considerations, but one may also wish to consider the strategic and time value (“freshness”) of the data.
Moving forward we'll be examining a number of business intelligence concepts and trends in more detail. Also, I'll be updating this blog a bit less frequently. I hope to post two to three times per week instead of Monday through Friday.
1. BI data have a distinct lifecycle that consists of Capture, Processing, Consumption, and Archival.
2. The more accurately and precisely data are captured at the beginning of the lifecycle, the less work will need to be done in processing later.
3. BI data should be maintained separately from daily transaction data if at all possible.
4. Data integration and governance processes are critical to getting the most out of your firm’s business intelligence. These processes may be formal or informal, but ignore them at your peril.
5. The key to ensuring that steps 3 and 4 are executed properly is extraction, transformation, and loading of data (ETL) from the transaction system where the data are captured to the data warehouse or other data store where they will be consumed.
6. Your choices for consuming data are conditioned on the kinds of questions you want to ask and how you want to interact with the data.
7. Humans interact with data in one or more of five ways: producing, reviewing, investigating, monitoring, and extrapolating (PRIME).
8. Archival policy for BI data may be driven mainly by legal or tax considerations, but one may also wish to consider the strategic and time value (“freshness”) of the data.
Moving forward we'll be examining a number of business intelligence concepts and trends in more detail. Also, I'll be updating this blog a bit less frequently. I hope to post two to three times per week instead of Monday through Friday.
Tuesday, January 11, 2011
Archiving Data
The last phase of the BI life-cycle is archival of BI data. We will spend relatively little time on this topic, mainly because data archival is a subject area that ranges outside the normal scope of business intelligence policy. Archival policy is generally dictated by legal and tax considerations.
Before data processing and mass electronic storage capabilities were widely available to business firms, archival policies were driven as much by financial and space constraints as by legally mandated document retention requirements. Now, with the advent of cheap electronic storage, legal and tax considerations are dominant in the decision to archive or destroy data. Of course, to the extent that local jurisdictions require source business documents to be archived in their original physical form there may still be a significant storage cost associated with maintaining archives.
With cheap electronic storage there is a temptation to keep everything. In the case of business intelligence data, this is not necessarily a good idea. If you have latitude to set archival policy for your BI data, here are a few common-sense suggestions.
Focus on strategic data. There is a diminishing return associated with archiving historical data at progressively lower levels of detail. For example, there may be little or no interest in knowing about sales of a particular USB hub five years ago, but there may be useful insights to be gleaned from examining the five-year trend in sales of USB hubs as a product class.
Data are like breadcrumbs: both become increasingly stale with the passage of time. With the pace of business activity constantly accelerating, the older the data, the less useful. This is especially true in cases where a company has pushed into new markets and left old ones behind. Although having some historical information about “the old days” may be interesting, from a BI perspective it does not add value.
Consider the industry and product functionality. It might make sense for an automaker to keep older historical data on sales of sedans, because the product class “sedan” has been stable for decades. By the same token it might make sense for a computer maker to keep older data about “laptops.” Even though the technology behind a laptop computer has changed dramatically since its introduction, the core functionality of the product arguably has not.
Before data processing and mass electronic storage capabilities were widely available to business firms, archival policies were driven as much by financial and space constraints as by legally mandated document retention requirements. Now, with the advent of cheap electronic storage, legal and tax considerations are dominant in the decision to archive or destroy data. Of course, to the extent that local jurisdictions require source business documents to be archived in their original physical form there may still be a significant storage cost associated with maintaining archives.
With cheap electronic storage there is a temptation to keep everything. In the case of business intelligence data, this is not necessarily a good idea. If you have latitude to set archival policy for your BI data, here are a few common-sense suggestions.
Focus on strategic data. There is a diminishing return associated with archiving historical data at progressively lower levels of detail. For example, there may be little or no interest in knowing about sales of a particular USB hub five years ago, but there may be useful insights to be gleaned from examining the five-year trend in sales of USB hubs as a product class.
Data are like breadcrumbs: both become increasingly stale with the passage of time. With the pace of business activity constantly accelerating, the older the data, the less useful. This is especially true in cases where a company has pushed into new markets and left old ones behind. Although having some historical information about “the old days” may be interesting, from a BI perspective it does not add value.
Consider the industry and product functionality. It might make sense for an automaker to keep older historical data on sales of sedans, because the product class “sedan” has been stable for decades. By the same token it might make sense for a computer maker to keep older data about “laptops.” Even though the technology behind a laptop computer has changed dramatically since its introduction, the core functionality of the product arguably has not.
Monday, January 10, 2011
"Real-World" Story #3
Here's an example of another dynamic to consider when deciding how to interact with data: the data themselves.
Once upon a time I was something of an expert in an area of business intelligence called Online Analytical Processing (OLAP). The idea behind OLAP is very similar to what we’ve discussed here previously about data warehousing. But the acronym “OLAP” is often associated in the BI world with a specific type of database that isn’t like the table-based databases we’ve discussed to this point. This type of OLAP database can be loaded into a spreadsheet like Excel so that you can investigate data (the “I” in our “PRIME” model) without having to learn a programming language. These kinds of databases are very handy for dealing with aggregations of numbers. Finance and accounting people love them.
A few years ago I entered into a consulting engagement with a company in the retail industry. When I arrived on the scene they were in the middle of developing an OLAP database application for labor management. There was a problem: the subject data were primarily textual in nature, not at all suitable for analysis using the number crunching OLAP database that had been selected for the task. Apparently the labor management group had seen a presentation of the OLAP database by the finance and accounting group and decided then and there that they, too, had to have an OLAP database. Never mind that the OLAP database made little or no sense for the kind of data they were analyzing. No amount of presentation, expert testimony, or cajoling would convince them to consider an alternative. Once the budget was allocated and the money spent, there was no turning back.
In the end we were able to build the application the customer wanted by associating a count of “1” with each bit of textual data so there would be something numeric for the OLAP database engine to crunch. We code-named the resulting solution “Chitty Chitty Bang Bang” after the flying car of the 1960s Walt Disney film. And we all lived happily ever after.
Once upon a time I was something of an expert in an area of business intelligence called Online Analytical Processing (OLAP). The idea behind OLAP is very similar to what we’ve discussed here previously about data warehousing. But the acronym “OLAP” is often associated in the BI world with a specific type of database that isn’t like the table-based databases we’ve discussed to this point. This type of OLAP database can be loaded into a spreadsheet like Excel so that you can investigate data (the “I” in our “PRIME” model) without having to learn a programming language. These kinds of databases are very handy for dealing with aggregations of numbers. Finance and accounting people love them.
A few years ago I entered into a consulting engagement with a company in the retail industry. When I arrived on the scene they were in the middle of developing an OLAP database application for labor management. There was a problem: the subject data were primarily textual in nature, not at all suitable for analysis using the number crunching OLAP database that had been selected for the task. Apparently the labor management group had seen a presentation of the OLAP database by the finance and accounting group and decided then and there that they, too, had to have an OLAP database. Never mind that the OLAP database made little or no sense for the kind of data they were analyzing. No amount of presentation, expert testimony, or cajoling would convince them to consider an alternative. Once the budget was allocated and the money spent, there was no turning back.
In the end we were able to build the application the customer wanted by associating a count of “1” with each bit of textual data so there would be something numeric for the OLAP database engine to crunch. We code-named the resulting solution “Chitty Chitty Bang Bang” after the flying car of the 1960s Walt Disney film. And we all lived happily ever after.
Friday, January 7, 2011
Consuming Data: The PRIME Model and Applications
We've discussed the ways in which humans interact with data and most recently how the activities of the PRIME model map to job functions. Last but not least we turn our attemtion to the kinds of applications that make sense for each activity.
Produce
Once data are discovered as a result of investigation, creating the data is essentially a data entry function. So from my viewpoint any application that allows data entry into an appropriate record system would work fine for this activity.
Review
My viewpoint on this should be pretty clear by now if you've followed this thread. Review activity is best suited to a reporting application.
Investigate
There are a wide variety of applications available for analysis or investigation, ranging from spreadsheets to web-based visualization tools and data mining. The application space for this function is crowded with vendors including Microsoft, IBM, Cognos, SAP Business Objects, Oracle, Microstrategy, SAS, and numerous others.
Monitor
The monitor function lends itself to applications like dashboard builders and other applications like scorecards and similar performance management tools.
Extrapolate
The applications for this activity will generally be more specialized and may be industry-specific, and may include tools for campaign management, predictive analytics, actuarial analysis, econometrics, and others.
Produce
Once data are discovered as a result of investigation, creating the data is essentially a data entry function. So from my viewpoint any application that allows data entry into an appropriate record system would work fine for this activity.
Review
My viewpoint on this should be pretty clear by now if you've followed this thread. Review activity is best suited to a reporting application.
Investigate
There are a wide variety of applications available for analysis or investigation, ranging from spreadsheets to web-based visualization tools and data mining. The application space for this function is crowded with vendors including Microsoft, IBM, Cognos, SAP Business Objects, Oracle, Microstrategy, SAS, and numerous others.
Monitor
The monitor function lends itself to applications like dashboard builders and other applications like scorecards and similar performance management tools.
Extrapolate
The applications for this activity will generally be more specialized and may be industry-specific, and may include tools for campaign management, predictive analytics, actuarial analysis, econometrics, and others.
Thursday, January 6, 2011
Consuming Data: The PRIME Model and Business Functions
Now that we've thought about how humans interact with data, let's discuss it in the context of business functions. Certain types of data consumption activities make more sense for some professionals than for others.
Produce/Investigate
I believe that investigation is best suited to trained knowledge workers where they are available, especially if the business is large. Obviously, if the business is a startup there may be little or no need for investigation, since the owner is knee-deep in the business on a daily basis. The tricky spot is where the business is small, but not so small that the owner can have detailed knowledge of all business activities on a daily basis. Then, the owner or top manager may have no other choice than to roll up her sleeves if she really wants insight into the data.
Since production of data outside the Capture or Process stages of the BI data life-cycle is so closely tied to investigation (as discussed in an earlier article), it only makes sense for these two activities to be performed together.
Review
Passive consumption of static data is best suited for the corporate board of directors (where applicable), executive management, or the public.
Monitor
Monitoring is best suited for line managers and executives (as long as the presentation is not too detailed).
Extrapolate
Extrapolation is definitely a specialized knowledge worker activity, because it usually requires knowledge of concepts such as statistical modeling.
Next Topic: PRIME And Applications
Produce/Investigate
I believe that investigation is best suited to trained knowledge workers where they are available, especially if the business is large. Obviously, if the business is a startup there may be little or no need for investigation, since the owner is knee-deep in the business on a daily basis. The tricky spot is where the business is small, but not so small that the owner can have detailed knowledge of all business activities on a daily basis. Then, the owner or top manager may have no other choice than to roll up her sleeves if she really wants insight into the data.
Since production of data outside the Capture or Process stages of the BI data life-cycle is so closely tied to investigation (as discussed in an earlier article), it only makes sense for these two activities to be performed together.
Review
Passive consumption of static data is best suited for the corporate board of directors (where applicable), executive management, or the public.
Monitor
Monitoring is best suited for line managers and executives (as long as the presentation is not too detailed).
Extrapolate
Extrapolation is definitely a specialized knowledge worker activity, because it usually requires knowledge of concepts such as statistical modeling.
Next Topic: PRIME And Applications
Wednesday, January 5, 2011
PRIME Model: An Integrated View
Having previously discussed the individual data consumption activities, let us now look at how they work together. My idea of an integrated conceptual view is presented in the chart below.

First, note that some data consumption activities have a specific time orientation. Review is focused on past events or data, monitoring on present events or data, and extrapolation on future events or data. Production and investigation of data occur in the present.
Second, there is typically a very specific flow in data consumption patterns, as depicted by the arrows in the chart. Review and monitoring activities typically trigger investigation as to why results (in the case of review) or current conditions (in the case of monitoring activity) are positive or negative. To reflect this I placed an arrow pointing from both of these activities to the investigate activity. Investigation activity often leads to the production of new data, and so I also include an arrow pointing from the investigate activity to the produce activity.
As we pointed out in an earlier article the production of data is also a standalone activity, such as when data are created in earlier stages of the BI data life-cycle. To be precise I probably should also include arrow from the produce activity to the review, monitor, and extrapolate activities. But in the interest of keeping the chart from becoming too cluttered I have omitted them here, and focus on data production as a by-product of data consumption.
Extrapolation is a bit different than reviewing and monitoring in that the assumptions used in extrapolation are typically developed through an investigation process. So there are arrows going both ways between these activities.
Next Topic: PRIME And Business Functions

First, note that some data consumption activities have a specific time orientation. Review is focused on past events or data, monitoring on present events or data, and extrapolation on future events or data. Production and investigation of data occur in the present.
Second, there is typically a very specific flow in data consumption patterns, as depicted by the arrows in the chart. Review and monitoring activities typically trigger investigation as to why results (in the case of review) or current conditions (in the case of monitoring activity) are positive or negative. To reflect this I placed an arrow pointing from both of these activities to the investigate activity. Investigation activity often leads to the production of new data, and so I also include an arrow pointing from the investigate activity to the produce activity.
As we pointed out in an earlier article the production of data is also a standalone activity, such as when data are created in earlier stages of the BI data life-cycle. To be precise I probably should also include arrow from the produce activity to the review, monitor, and extrapolate activities. But in the interest of keeping the chart from becoming too cluttered I have omitted them here, and focus on data production as a by-product of data consumption.
Extrapolation is a bit different than reviewing and monitoring in that the assumptions used in extrapolation are typically developed through an investigation process. So there are arrows going both ways between these activities.
Next Topic: PRIME And Business Functions
Tuesday, January 4, 2011
PRIME Model: Extrapolate Category
In previous articles we discussed aspects of data consumption that involved either the past (review), the present (monitoring), or elements of both (producing and investigating). Unlike reviewing or monitoring, extrapolation attempts to predict future data. This usually takes one of two forms: forecasting (the estimation of key data values in the future based on current values and trends), and predicting outcomes (using statistical probabilities of various events).
The goal of extrapolation activity is to either identify opportunities before they become known to other market participants or to identify and counter future threats before they occur. An example of the former would be an attempt to project which customers are most likely to respond to a marketing campaign in order to most effectively target advertising. An example of the latter would be to attempt to determine which of your best customers is most likely to take his or her business elsewhere; armed with this knowledge one could prevent the impending defection and retain the customer.
Extrapolation entails more risk than other data consumption activities because one must make assumptions about future conditions. Because conditions are subject to change between the time of extrapolation and the future data or conditions to be extrapolated, extrapolations are frequently expressed as scenarios. Different scenarios are created based on differing assumptions about how current trends will play out, and decision makers choose the scenario they believe is most likely to occur and use the chosen scenario to guide the decision process. Other scenarios can be taken into account by the decision makers in creating contingency plans.
Next Topic: PRIME - An Integrated View
The goal of extrapolation activity is to either identify opportunities before they become known to other market participants or to identify and counter future threats before they occur. An example of the former would be an attempt to project which customers are most likely to respond to a marketing campaign in order to most effectively target advertising. An example of the latter would be to attempt to determine which of your best customers is most likely to take his or her business elsewhere; armed with this knowledge one could prevent the impending defection and retain the customer.
Extrapolation entails more risk than other data consumption activities because one must make assumptions about future conditions. Because conditions are subject to change between the time of extrapolation and the future data or conditions to be extrapolated, extrapolations are frequently expressed as scenarios. Different scenarios are created based on differing assumptions about how current trends will play out, and decision makers choose the scenario they believe is most likely to occur and use the chosen scenario to guide the decision process. Other scenarios can be taken into account by the decision makers in creating contingency plans.
Next Topic: PRIME - An Integrated View
Monday, January 3, 2011
PRIME Model: Monitoring Category
Monitoring is conceptually similar to reviewing, but differs in a couple of key respects. First, review activity typically takes place using historical data after a business cycle is complete, while monitoring occurs on a continuous basis with the latest available data. Second, because the subject of a review is typically historical in nature, the audit requirements involved should be expected to be greater than those for data being monitored. (This is not to imply that inaccuracy in any data should be considered acceptable.)
Previously, we noted that the subject of a review process is typically a report. Although you can use reports for monitoring purposes as well, a report may not be the best medium for monitoring. Most managers flip their P/L or income statement to the section of greatest interest to them. The higher up the organizational chart they sit, the farther back in the report they go. Similarly, department heads will focus more keenly on the parts of the report that concern their parts of the business. Given this tendency, it makes good sense to provide those who monitor business processes with only the specific data they need. This leads to the notion of key performance indicators, or KPIs, which we will discuss in greater detail in a future article.
Next Topic: Extrapolate
Previously, we noted that the subject of a review process is typically a report. Although you can use reports for monitoring purposes as well, a report may not be the best medium for monitoring. Most managers flip their P/L or income statement to the section of greatest interest to them. The higher up the organizational chart they sit, the farther back in the report they go. Similarly, department heads will focus more keenly on the parts of the report that concern their parts of the business. Given this tendency, it makes good sense to provide those who monitor business processes with only the specific data they need. This leads to the notion of key performance indicators, or KPIs, which we will discuss in greater detail in a future article.
Next Topic: Extrapolate
Subscribe to:
Comments (Atom)